El Precio de la Precisión: Medimos Itask(ϵ) con Python (Primer Paso hacia el Límite Físico)
Inicia sesión para descargarUn tutorial profundo que une la Teoría de Señales (SDR) con la Inteligencia Artificial. Construimos un laboratorio en Python desde cero para estimar Itask(ϵ), la frontera óptima costo-error. Aprende a calibrar tu …
¡Hola, comunidad!
En tucodigocotidiano, especialmente en nuestra sección de “Señales y SDR”, estamos obsesionados con la eficiencia: cómo comprimir, transmitir y reconstruir señales (el mundo de R(D) de Shannon).
Pero, ¿qué pasa si nuestro objetivo no es reconstruir la señal, sino solo entenderla? ¿Si solo queremos saber si esa señal es “BPSK” o “QPSK”? ¿Cuál es la cantidad mínima de información que debemos retener para esa tarea?
Hoy, damos el primer paso hacia un tema increíblemente profundo: el límite físico de la computación. Antes de poder hablar de la energía (E) que gasta un algoritmo, primero debemos saber cuánta información (I) necesita procesar.
Vamos a construir un laboratorio en Python para estimar esta cantidad fundamental: Itask(ε), la frontera óptima costo-error.
Objetivo: ¿Qué es Itask(ε)?
Imaginemos nuestro problema:
- X = La Entrada: Una trama de datos de un SDR. (Muchos datos).
- Y = La Tarea: ¿Es modulación “A” o “B”? (Respuesta simple).
- T = El Resumen: Una “representación comprimida” o “cuello de botella” que creamos a partir de X.
- ε (épsilon) = El Error Máximo: Nuestro estándar de calidad (ej., ε = 0.01 o 1% de error).
Queremos que T sea lo más pequeño posible, pero que aún nos permita realizar la tarea Y.
La frontera teórica que define esto es Itask(ε). Es la solución al siguiente problema de optimización:
Traducción: Es la frontera óptima costo-error. Nos dice cuántos bits de \(X\) (medidos como Información Mutua \(I(X;T)\)) debe retener nuestra representación \(T\) para lograr un error \(\epsilon\).
Como este problema es intratable, vamos a estimarlo numéricamente.
Nuestro Laboratorio: Un Experimento en Dos Modos
Nuestro script (itask_estimator.py) tiene dos modos:
- Modo 1 (
gaussian_rd): Calibración. - Modo 2 (
ib_discrete): Medición.
Modo 1: La Calibración (el “patrón de oro” de “Señales”)
Validamos nuestro instrumento con el caso clásico de Shannon que sí conocemos:
Este es el mundo de “Señales y SDR”. La Gráfica 1 muestra el resultado de nuestro script.
![Curva Gaussian RD: I_task = R(D) [bits] frente a la distorsión MSE (D) en escala logarítmica.](https://tucodigocotidiano.yarumaltech.com/files/o3_fig_gaussian_rd.png)
Análisis de la Gráfica 1: La línea es perfectamente recta en una escala logarítmica, coincidiendo con la pendiente teórica de la fórmula. Veredicto: ¡Calibración exitosa! Nuestro script reporta bits usando \( \log_2 \) correctamente.
Modo 2: La Medición Real (IB Discreto)
Ahora, usamos el Information Bottleneck (IB) para atacar el problema real. El método “barre” un parámetro de equilibrio \((\beta)\) para generar muchos puntos de (Error, Costo).
Si graficamos los resultados “en bruto”, obtenemos esto:
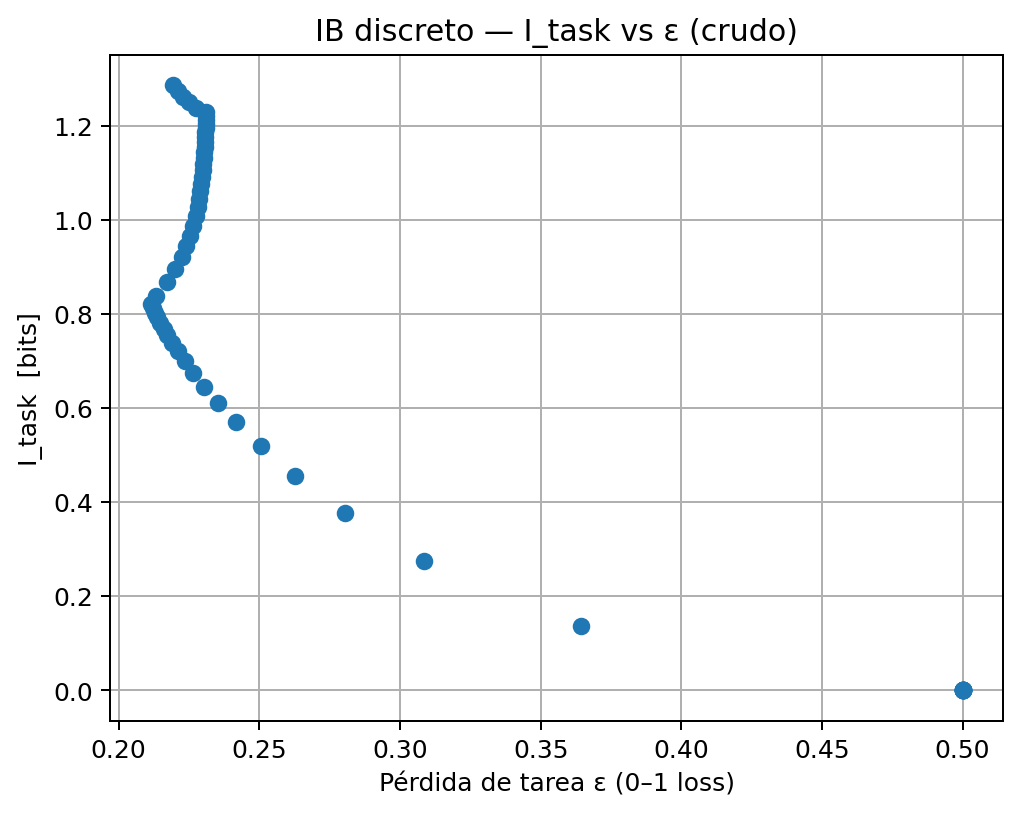
Análisis de la Gráfica 2: Vemos una nube de puntos caótica. Esto es crucial: el algoritmo de optimización se atasca en óptimos locales. Para un mismo error, encuentra soluciones con costos muy diferentes.
El Análisis: Develando la Frontera (La “Limpieza”)
Sabemos que la frontera óptima \(I_{\text{task}}(\epsilon)\) debe ser monotónica (menos error no puede costar menos bits). Así que aplicamos un filtro (enforce_monotone...) que toma el “caos” de la Gráfica 2 y traza la envolvente monótona, la frontera de los mejores puntos que encontró.
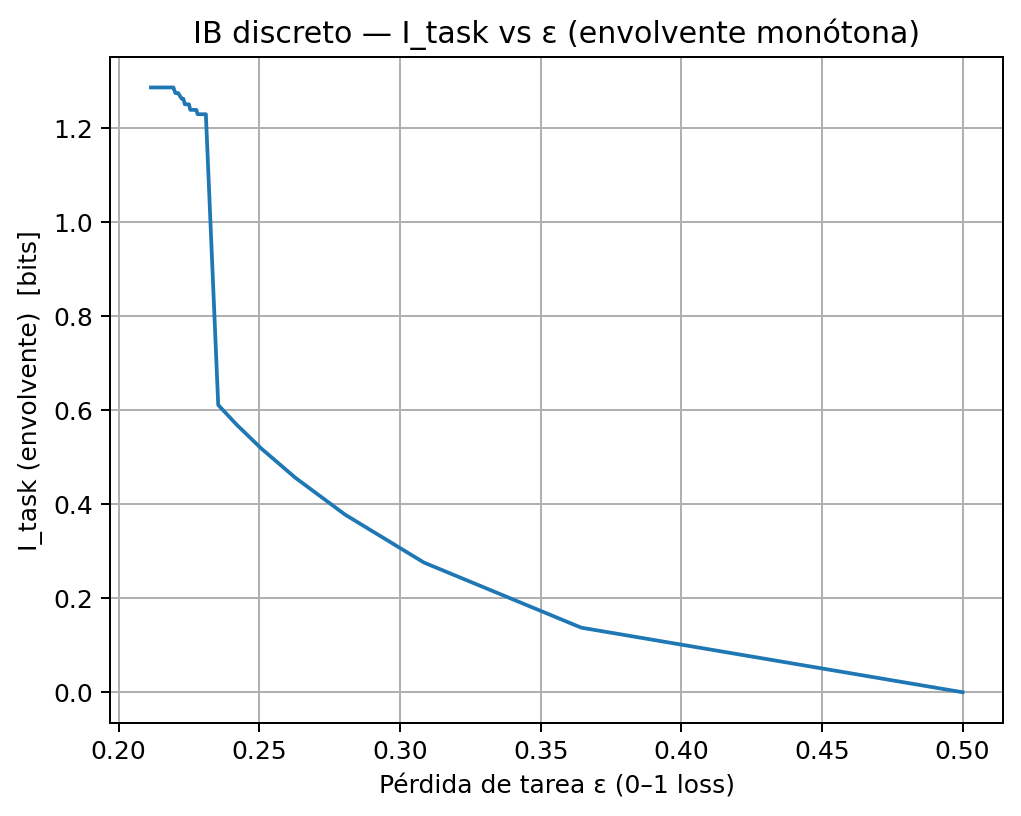
Análisis de la Gráfica 3: Esta curva es nuestra aproximación de \(I_{\text{task}}(\epsilon)\). Es el resultado final de nuestro experimento. No es la “verdadera” curva teórica (que es inalcanzable), sino la mejor estimación que pudimos encontrar con nuestros parámetros (tamaño de resumen \(T = 5\) y 60 puntos de \(\beta\)).
Comentarios y valoraciones
No hay comentarios aún. ¡Sé el primero en opinar!