RAG sin frameworks: troceo + embeddings + coseno en 1 archivo
Inicia sesión para descargarAprende a construir un sistema RAG (Retrieval-Augmented Generation) completo desde cero sin depender de librerías externas. Este tutorial explora la ingeniería detrás de la recuperación de información, implementando troceo inteligente (smart chunking), …
Contenido del tutorial ⌄
- Ingeniería de RAG Nativo
- 1. RAG desde Cero y sin Magia
- 2. Teoría: De Texto a Vectores (Sin Código)
- A. Chunking (El Troceo)
- B. Embeddings (Semántica Numérica)
- C. Similitud Coseno (La Búsqueda)
- 3. La Arquitectura OOP (El Plano)
- 4. Análisis del Código: Construyendo el Sistema
- Bloque A: Tipos Base y Carga de Datos
- Bloque B: El Chunker Inteligente
- Bloque C: El Embedder Didáctico y Matemático
- Bloque D: El Motor de Búsqueda Vectorial
Ingeniería de RAG Nativo
¿Cómo funciona realmente la "recuperación" de datos en IA sin depender de librerías mágicas? En este post destripamos el pipeline de un sistema RAG desde sus bases matemáticas. Construiremos un motor completo en Python usando NumPy, implementando troceo inteligente y búsquedas por Similitud Coseno desde cero.
El desafío de este sistema no es solo programar, sino entender cómo la geometría del espacio vectorial nos permite encontrar respuestas. Olvida por un momento LangChain; hoy vamos a ser nosotros quienes dictemos las reglas del contexto.
Troceo de documentos con solapamiento (overlap) y respeto a límites gramaticales para no perder el contexto.
Un modelo de representación semántica determinista y ultra-ligero basado en hashing estable y log-scaling.
Implementación optimizada de Similitud Coseno usando productos matriciales para búsquedas en milisegundos.
1. RAG desde Cero y sin Magia
Hoy en día, construir un sistema RAG (Retrieval-Augmented Generation) parece requerir magia oscura. Importamos librerías masivas como LangChain o LlamaIndex, escribimos tres líneas de código y, de repente, nuestro bot responde preguntas sobre nuestros PDFs. Pero, ¿qué pasa cuando falla? ¿Qué pasa cuando necesitamos optimizarlo? Como todo es una caja negra, nos quedamos atascados.
En este tutorial vamos a destruir la caja negra. Vamos a construir un sistema RAG completo y funcional utilizando únicamente Python puro, NumPy y Arquitectura OOP. Entenderemos las matemáticas detrás de las búsquedas y cómo viaja la información desde un documento de texto hasta el cerebro de un LLM.
Antes de escribir código, observemos el viaje de la información. Este es el "Pipeline" o tubería conceptual que vamos a construir:
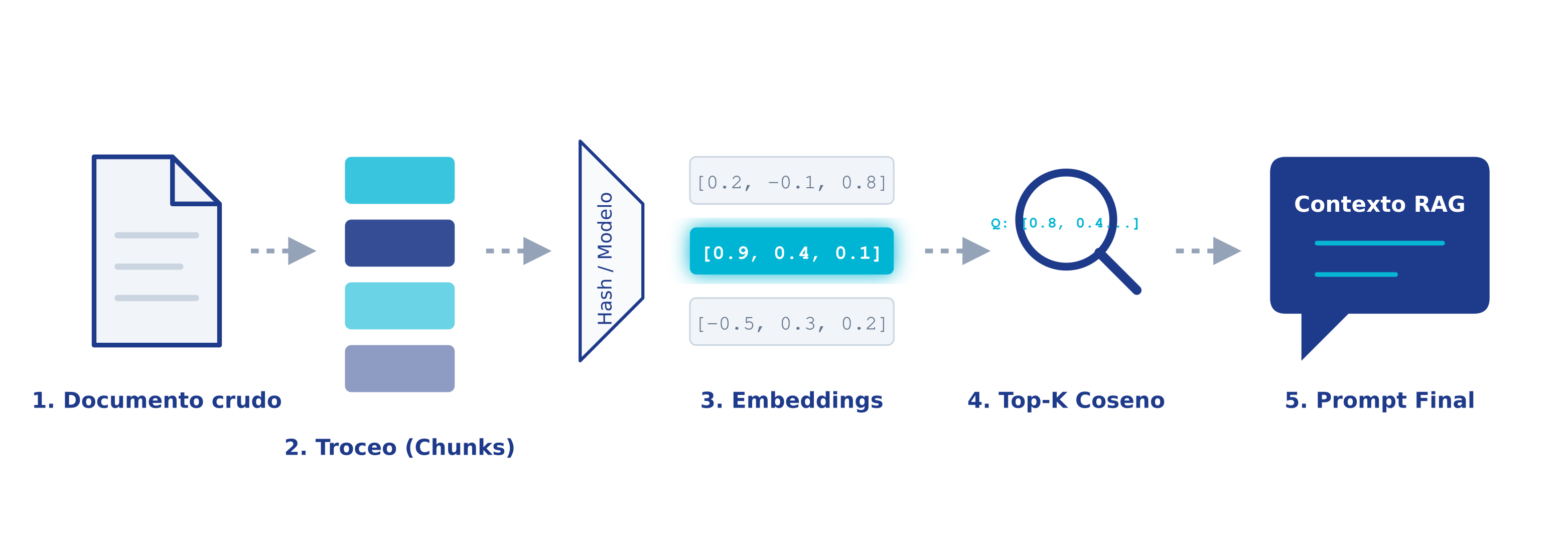
2. Teoría: De Texto a Vectores (Sin Código)
Para que un modelo de Inteligencia Artificial pueda buscar en tus documentos, primero debemos traducir el lenguaje humano al idioma nativo de las máquinas: los números y la geometría. Este proceso tiene tres fases fundamentales.
A. Chunking (El Troceo)
No puedes meter un libro de 500 páginas en un LLM de golpe. Debemos dividirlo en fragmentos manejables llamados Chunks. Sin embargo, si cortamos el texto de forma bruta, podemos partir una idea a la mitad. Para evitar perder el hilo conductor, utilizamos una técnica llamada Overlap (Solapamiento), donde el final de un chunk es el inicio del siguiente, preservando el contexto.
B. Embeddings (Semántica Numérica)
Una vez tenemos los fragmentos de texto, pasamos cada uno por un modelo de Embeddings. Este modelo lee el texto y devuelve una lista de números (un vector). Lo mágico de los embeddings es que mapean el significado: si dos textos hablan de lo mismo, sus vectores apuntarán hacia la misma dirección en un espacio multidimensional.
C. Similitud Coseno (La Búsqueda)
Cuando el usuario hace una pregunta, la convertimos en un vector usando el mismo modelo. ¿Cómo encontramos el fragmento de texto que tiene la respuesta? Calculando la distancia geométrica entre el vector de la pregunta y todos los vectores de nuestros fragmentos.
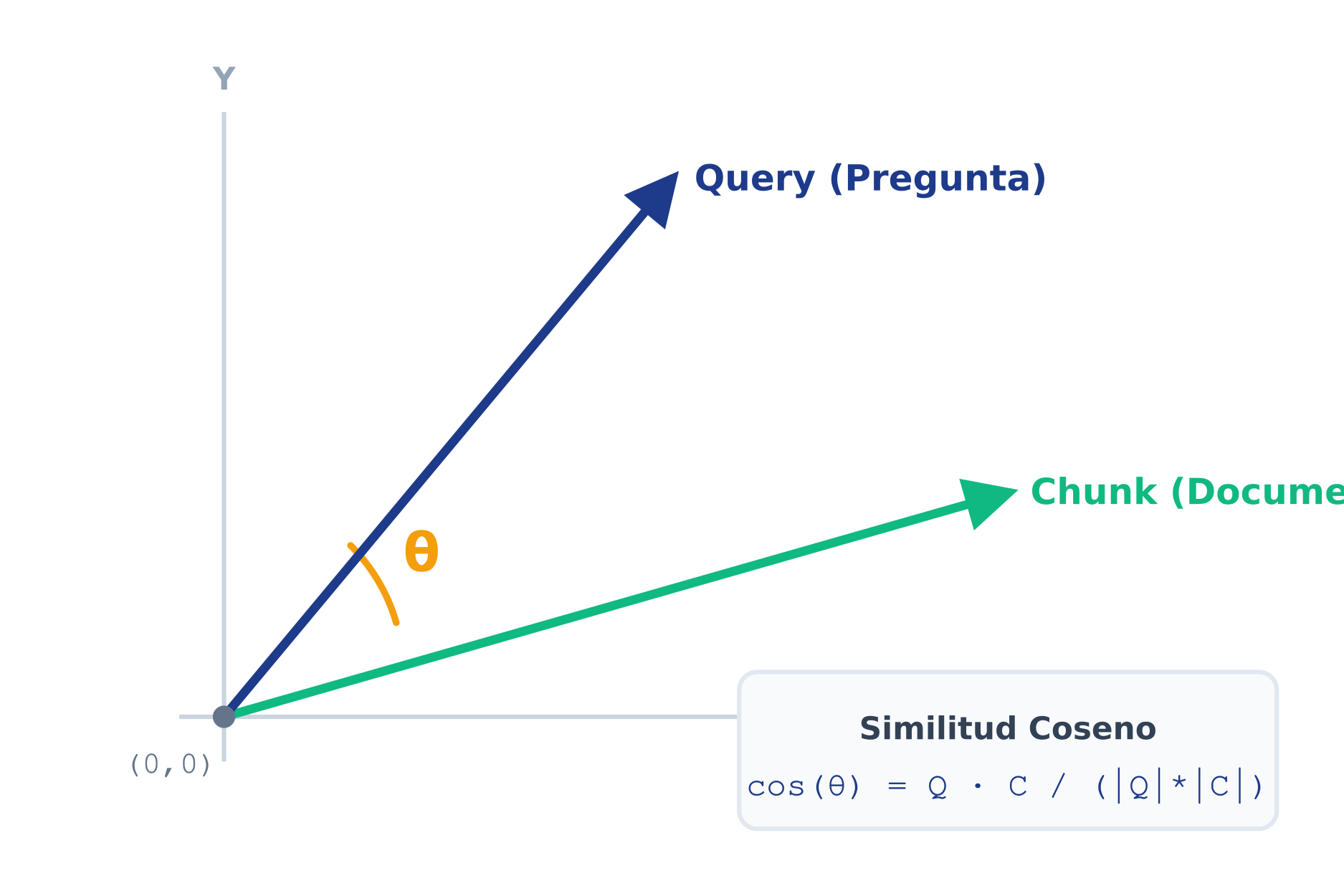
En inteligencia artificial, rara vez medimos la distancia con una regla recta (Euclidiana). En su lugar, medimos el ángulo entre las flechas. A menor ángulo, mayor similitud temática. Esto se llama Similitud Coseno, y matemáticamente se expresa así:
$$ \cos(\theta) = \frac{A \cdot B}{\|A\| \|B\|} $$El truco de rendimiento: Si nuestros vectores $A$ y $B$ están normalizados (es decir, su longitud o magnitud $\|A\|$ y $\|B\|$ es exactamente igual a 1), el divisor desaparece. La fórmula entera se reduce a un simple producto punto ($A \cdot B$), una operación que las computadoras (y NumPy) pueden ejecutar millones de veces por segundo.
🧩 Sobre el tamaño del Chunk y el Overlap
No existe un tamaño perfecto. Un chunk muy pequeño (100 caracteres) perderá el contexto global de la frase. Un chunk muy grande (2000 caracteres) diluirá el significado y confundirá a la Similitud Coseno. La industria suele utilizar tamaños entre 500 y 1000 tokens, con un overlap (solapamiento) del 10% al 20%.
📐 ¿Por qué Similitud Coseno y no Euclidiana?
La distancia Euclidiana mide la longitud de la línea recta que separa las puntas de dos vectores. Es muy sensible a la frecuencia de las palabras. Si un texto es muy largo y menciona "Python" 50 veces, su vector será larguísimo. La Similitud Coseno ignora la longitud del vector y solo se fija en la dirección (la semántica pura), haciéndola perfecta para comparar textos cortos (la pregunta) contra textos largos (los fragmentos de documentos).
3. La Arquitectura OOP (El Plano)
Ya conocemos la teoría y las matemáticas. Ahora vamos a convertir esos conceptos en un plano de software. Para que nuestro código no se convierta en un desastre monolítico, usaremos Programación Orientada a Objetos (OOP) con responsabilidades únicas y claramente definidas.
Nuestro sistema estará compuesto por 5 pilares principales:
- 📝 DocumentLoader: El operario. Su única función es leer archivos de disco y convertirlos en texto en memoria, manejando errores de codificación (UTF-8).
- ✂️ Chunker: El cirujano. Corta los documentos en fragmentos manejables respetando saltos de línea para no dejar palabras a medias.
- 🧠 Embedder: El traductor. Convierte el texto humano a arreglos de NumPy (vectores) y se asegura de aplicar la Normalización L2 (esencial para el producto punto).
- 🗄️ VectorIndex: El bibliotecario matemático. Almacena las matrices de números y ejecuta la búsqueda por Similitud Coseno a altísima velocidad.
- ⚙️ RAGEngine: El director de orquesta. Conecta las piezas anteriores, guarda/carga el progreso en el disco duro y empaqueta la respuesta final lista para un LLM.
Tenemos la teoría y tenemos los planos. En la siguiente sección, abrimos el editor de código y comenzamos a programar.
4. Análisis del Código: Construyendo el Sistema
En lugar de usar librerías externas que oculten la lógica, escribiremos todo en Python usando únicamente numpy. Vamos a dividir nuestro sistema RAG en 5 bloques lógicos.
Bloque A: Tipos Base y Carga de Datos
El primer paso es definir cómo lucirá la información dentro de nuestra aplicación. Usaremos @dataclass(frozen=True) para crear estructuras inmutables. Esto significa que una vez que un documento entra al sistema, nadie puede modificarlo por error, garantizando la integridad de los datos. Luego, crearemos el DocumentLoader, encargado de barrer nuestras carpetas buscando archivos de texto.
from __future__ import annotations
import os
from dataclasses import dataclass
from typing import Dict, List
# -------------------------
# Tipos base (Inmutables)
# -------------------------
@dataclass(frozen=True)
class Document:
doc_id: str
text: str
meta: Dict[str, str]
@dataclass(frozen=True)
class Chunk:
doc_id: str
chunk_id: str
text: str
meta: Dict[str, str]from __future__ import annotations
import os
from typing import List
from .types import Document
class DocumentLoader:
"""Carga .txt y .md de una carpeta (recursivo)."""
def __init__(self, exts: tuple[str, ...] = (".txt", ".md")):
self.exts = exts
def load_folder(self, folder: str) -> List[Document]:
docs: List[Document] = []
for root, _, files in os.walk(folder):
for fn in files:
if not fn.lower().endswith(self.exts):
continue
path = os.path.join(root, fn)
with open(path, "r", encoding="utf-8", errors="ignore") as f:
text = f.read()
doc_id = os.path.relpath(path, folder)
docs.append(Document(doc_id=doc_id, text=text, meta={"path": path}))
return docs❄️ El poder de frozen=True
En Python, los objetos suelen ser mutables. Al usar @dataclass(frozen=True), hacemos que Document y Chunk actúen como constantes. Si una función intenta hacer chunk.text = "nuevo texto", Python lanzará un error. Esto evita bugs muy difíciles de rastrear en sistemas complejos.
🛡️ Resiliencia en la codificación
El parámetro errors="ignore" en open() es un salvavidas. Si descargas miles de documentos de internet, siempre habrá alguno con un byte corrupto. Sin este parámetro, un solo archivo malo detendría toda la carga del sistema.
Bloque B: El Chunker Inteligente
Aquí es donde ocurre la magia del "overlap". Podríamos cortar la cadena de texto cada 900 caracteres, pero eso dejaría palabras cortadas a la mitad (ej: "inteligen" - "cia").
Para solucionarlo, nuestro Chunker buscará hacia atrás desde el límite (en una ventana de 120 caracteres) para encontrar un punto final, un salto de línea o un signo de exclamación. Si lo encuentra, corta ahí. Es un troceo que respeta la gramática.
from __future__ import annotations
from typing import List, Optional
from .types import Document, Chunk
class Chunker:
"""Trocea texto por caracteres con overlap.
- `max_chars`: tamaño máximo del chunk
- `overlap`: cuántos caracteres se repiten entre chunks
- `smart_boundary`: intenta cortar cerca del final en un límite natural (\n . ! ?)
"""
def __init__(self, max_chars: int = 900, overlap: int = 150, smart_boundary: bool = True, boundary_window: int = 120):
if overlap >= max_chars:
raise ValueError("overlap debe ser menor que max_chars")
self.max_chars = max_chars
self.overlap = overlap
self.smart_boundary = smart_boundary
self.boundary_window = boundary_window
self.boundaries = ("\n", ".", "!", "?")
def _find_boundary(self, text: str, start: int, end: int) -> Optional[int]:
# Busca hacia atrás, en una ventana corta, un punto de corte "natural"
w = min(self.boundary_window, end - start)
probe = text[end - w:end]
best = None
for b in self.boundaries:
j = probe.rfind(b)
if j != -1:
cut = (end - w) + j + 1 # incluye boundary
best = cut if (best is None or cut > best) else best
return best
def split(self, doc: Document) -> List[Chunk]:
text = doc.text.strip()
if not text:
return []
chunks: List[Chunk] = []
start = 0
i = 0
while start < len(text):
end = min(len(text), start + self.max_chars)
if self.smart_boundary and end < len(text):
cut = self._find_boundary(text, start, end)
if cut is not None and cut > start + int(self.max_chars * 0.6):
end = cut
piece = text[start:end].strip()
if piece:
chunks.append(
Chunk(
doc_id=doc.doc_id,
chunk_id=f"{doc.doc_id}::c{i}",
text=piece,
meta={
"start": str(start),
"end": str(end),
**doc.meta
},
)
)
i += 1
if end == len(text):
break
start = max(0, end - self.overlap)
return chunks🕵️♂️ Cómo funciona el _find_boundary
La función rfind() busca desde la derecha hacia la izquierda. Extraemos los últimos 120 caracteres de nuestro trozo potencial y buscamos el último signo de puntuación. Al usar cut > start + int(self.max_chars * 0.6), evitamos que un punto mal colocado cree un chunk enano (menos del 60% del tamaño permitido).
Bloque C: El Embedder Didáctico y Matemático
Normalmente, aquí llamarías a la API de OpenAI (que cuesta dinero) o usarías HuggingFace (que requiere descargar gigabytes de modelos). Como este es un tutorial educativo, construiremos un "Embedder Estadístico" usando la función hash blake2b de Python nativo.
Esto convierte palabras en posiciones dentro de un vector de 512 dimensiones. Además, implementaremos la Normalización L2, que es el requisito matemático indispensable para usar la Similitud Coseno de forma ultrarrápida.
from __future__ import annotations
import re
import hashlib
from typing import List
import numpy as np
_TOKEN_RE = re.compile(r"[a-z0-9áéíóúñü]+", re.IGNORECASE)
def l2_normalize(M: np.ndarray) -> np.ndarray:
norms = np.linalg.norm(M, axis=1, keepdims=True) + 1e-12
return M / norms
class Embedder:
def embed_texts(self, texts: List[str]) -> np.ndarray:
raise NotImplementedError
class HashingEmbedder(Embedder):
"""Embedder demo (estable, sin APIs).
- Tokeniza texto, y hace hashing estable a un vector de dimensión fija.
- No es SOTA, pero sirve perfecto para enseñar el pipeline end-to-end.
"""
def __init__(self, dim: int = 512):
self.dim = dim
def _stable_hash(self, token: str) -> int:
h = hashlib.blake2b(token.encode("utf-8"), digest_size=8).digest()
return int.from_bytes(h, "little", signed=False) % self.dim
def embed_texts(self, texts: List[str]) -> np.ndarray:
M = np.zeros((len(texts), self.dim), dtype=np.float32)
for i, t in enumerate(texts):
tokens = _TOKEN_RE.findall(t.lower())
for tok in tokens:
j = self._stable_hash(tok)
M[i, j] += 1.0
# sublineal para que "spam" de tokens no domine tanto
M = np.log1p(M)
return l2_normalize(M)📉 ¿Por qué usamos log1p?
Si un chunk repite la palabra "Python" 100 veces, esa dimensión en el vector se disparará, opacando el resto de palabras. np.log1p() (logaritmo natural de 1 + x) suaviza esos picos. "Python" 100 veces no valdrá 100, sino un número mucho menor, dando oportunidad a que otras palabras menos frecuentes también importen semánticamente.
📐 El secreto de + 1e-12
En la función l2_normalize sumamos 1e-12 (un número diminuto). ¿Por qué? Porque si pasamos un texto completamente vacío o símbolos irreconocibles, el vector será puro cero. La magnitud (norm) será 0. Dividir entre cero en NumPy rompería el programa. Ese pequeño número salva nuestra app de colapsar.
Bloque D: El Motor de Búsqueda Vectorial
Llegamos al cerebro de nuestra operación. El VectorIndex almacena en memoria la lista de fragmentos de texto (Chunks) y una gran matriz matemática con todos sus vectores (Embeddings).
Cuando el usuario hace una pregunta, la convertimos en un vector. ¿Cómo encontramos los textos más relevantes en milisegundos? Multiplicando el vector de la pregunta contra la matriz completa de la base de datos en un solo paso. Esta es la belleza del álgebra lineal aplicada.
Comentarios y valoraciones
No hay comentarios aún. ¡Sé el primero en opinar!